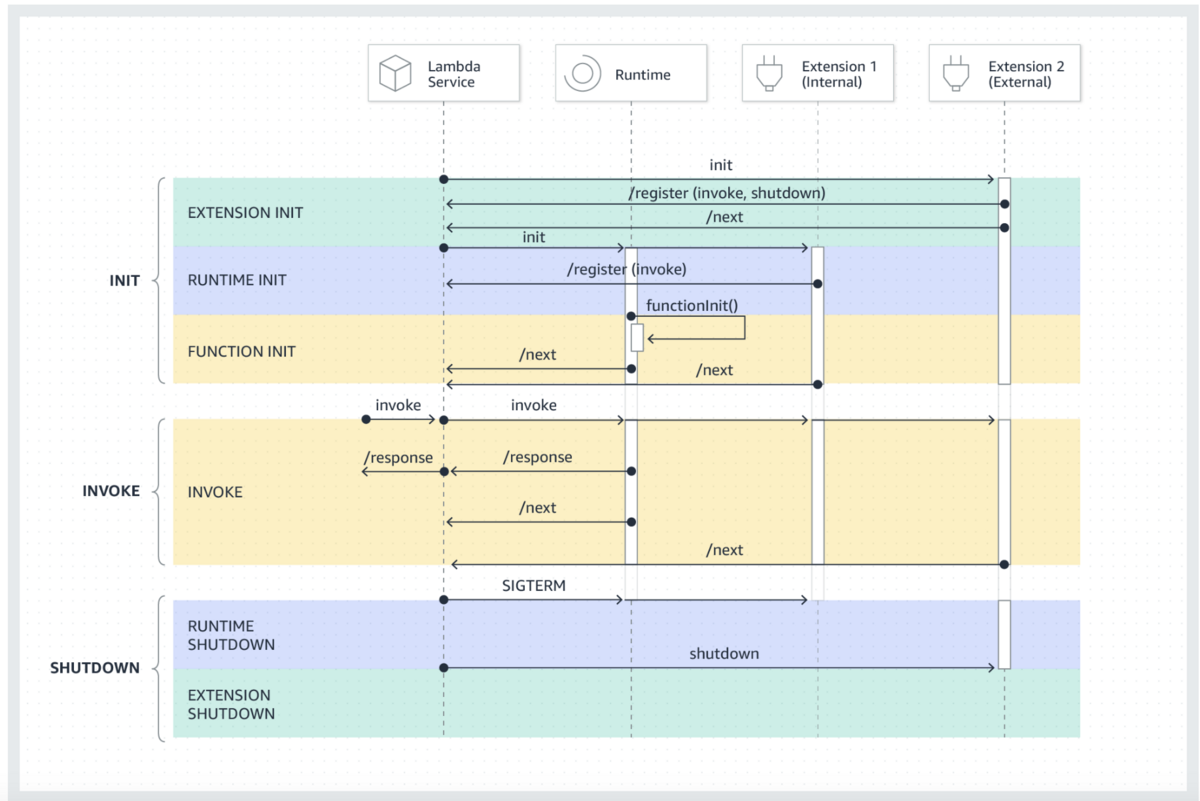
やりたいこと
Flutterで、Sliderの値に応じて表示されるテキスト内容を動的に変える機能をテストしたいケースがあった。しかし、Flutterのテストフレームワークでは、Sliderのドラッグ操作を行うために画面上でのドラッグ距離を指定する方法(Offset)しか提供されていない。Sliderの値に基づいて任意の位置に直接ドラッグする機能は提供されていない。
例)0から100の間の値をとるSliderがあるとして、値が70の位置にドラッグさせる
解決策: 最小値・最大値・目標値から位置を計算
WidgetTesterのextensionとして、この機能を実装した。
extension WidgetTesterExtensions on WidgetTester { Future<void> slideToValue(Finder sliderFinder, double value, double minValue, double maxValue) async { // スライダーの全幅を計算 final sliderWidth = getSize(sliderFinder).width; // 目標値が全体のどの位置にあるかを計算 final targetPosition = (value - minValue) / (maxValue - minValue); // スライダーの最初の位置を取得 final sliderStart = getTopLeft(sliderFinder); // ドラッグする位置を計算 final dragPosition = Offset(sliderStart.dx + sliderWidth * targetPosition, sliderStart.dy + getSize(sliderFinder).height / 2); // スライダーの中央位置を取得 final sliderCenter = getCenter(sliderFinder); // スライダーをドラッグする final gesture = await startGesture(sliderCenter); await pump(); await gesture.moveTo(dragPosition); await gesture.up(); await pumpAndSettle(); } }
このコードでは、スライダーの幅と位置を計算し、指定した値に応じた位置にスライダーをドラッグする処理を行っている。 途中で一度中央をタップする処理が入っているが、これはユーザーの動きを模したもの。なくても良い。
結果
この方法により、指定した値にかなり近い位置までスライダーをドラッグできるようになったが、若干の誤差が発生することがある。実際に、1から15の範囲を持つSliderを用意し、6の位置にドラッグしたのだが、5.7程度の位置になった。実装上、多少の誤差は避けられないかもしれない。
そのため、テストを書く際は、closeTo を使うなどして、一定の誤差を許容する必要がありそうだ。